It started with a one-line message from a finance team on a Tuesday afternoon: A handful of customers had been charged twice that day, and one was disputing a duplicate charge with their bank.
I went straight to the monitoring, expecting to find something broken. Instead, everything looked healthy: By the system’s own records, every order had been paid exactly once. It took the team a month of digging through production incidents to close the gap between a dashboard that said, “all good,” and a customer billed twice.
I’ve since seen this kind of failure across multiple payment systems, some handling hundreds of thousands of transactions a day. What follows is a composite and doesn’t describe any single system or organization. The numbers, timings and identifying details have been changed to keep anything proprietary out.
The retry that charged twice
A customer clicked Pay; the order service called the payment service, which called the external provider. The provider charged the card for $200 and recorded a success on its side.
The only thing that went wrong was timing. The provider was under load and took just over 3 seconds to answer. The client gave up after 2 seconds, a default inherited from internal service calls and never tuned for payments. From the caller’s side, the call had simply failed, so nothing was marked as paid.
The retry logic did what it was built to do and sent the request again. The provider saw what looked like a fresh charge and took the money a second time. The database recorded one payment: the retry. The first charge lived only in the provider’s records, invisible to us until the complaints came in.
Violetta Pidvolotska
The duplicates were refunded within hours, before the dispute could become a chargeback. Understanding what had actually failed took much longer.
Later, we widened the timeout well past the provider’s slowest healthy responses, but as long as a retry can trigger a second charge, a longer timeout only makes the double charge rarer.
The real mistake was older than the limit itself. The system had been told that a timeout means failure.
The third state
We tend to think of a network call as having two outcomes: it worked or it didn’t. A timeout is the third. The request may never have arrived. It may have done its work and lost the response on the way back. That is what bit us. Or it may still be running. From the caller’s side, you can’t tell which.
Code rarely has a separate path for “unknown.” It gets lumped in with failure and the failure path retries. When the request moves money, that is how you charge someone twice.
A slow service shows up as rising response times, an unreliable one as errors. A double charge shows up as a success, and nobody noticed until a customer did.
Timeouts, which I’ve written about before, turn silent hangs into visible failures. And visible failures get retried, which is how we arrived at idempotency.
“Exactly-once” gets used as if it were a setting you could turn on. You cannot promise exactly-once delivery across an unreliable network, as Tyler Treat explains. What you can promise is exactly-once effects: The request may arrive twice, while the charge happens once.
My first instinct was to stop retrying payments automatically and it helped. But not every retry is ours to switch off: The customer refreshes the page, or a retry policy somewhere in the infrastructure resends on its own.
The assumptions under the key
The standard remedy is an idempotency key: The caller attaches a unique value to one attempt at an operation and sends the same value on every retry. A new key gets processed and its result stored; a familiar one gets the stored result back, so the retry has no extra effect. Brandur Leach’s walkthrough of Stripe-like idempotency keys in Postgres lays the pattern out end to end.
The key was shipped and the duplicates stopped. But we relaxed too early. The key turned out to be the easy part.
A key like this rests on four assumptions. I’ve since turned them into a checklist I call the four-assumptions test:
- Claim. Claiming a key is just a matter of checking it’s free first.
- Intent. The same key always carries the same intent.
- Memory. Whatever a key remembers is safe to replay.
- Boundary. Nothing behind the key lies beyond your control.
Over the following month, all four broke: The race in a load test, the other three in production.
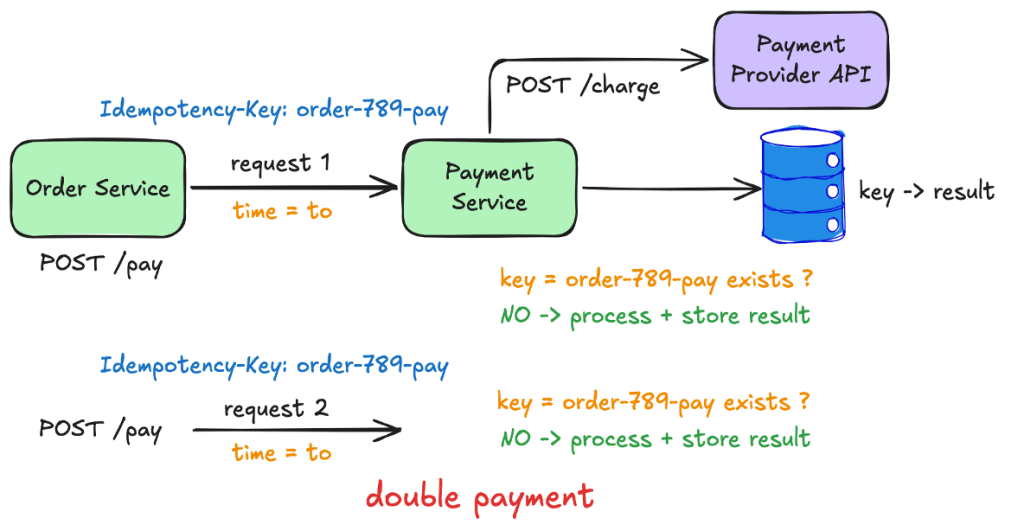
Two requests, same millisecond
In a load test, two requests with the same key arrived in the same millisecond. Each checked for the key; neither found it and both started processing.
Violetta Pidvolotska
“Check whether the key exists, then write it” is a race like any other and it broke the claim assumption. We fixed it by flipping the order: now writing the key is the check. Every request writes it as “started” and the database lets only one claim win. The safeguard:
-- Try to claim the key; the UNIQUE index lets only one caller win.
INSERT INTO operations (idempotency_key, state) VALUES (:key, 'started')
ON CONFLICT (idempotency_key) DO NOTHING;The insert touches one row or none, and that count tells you which path you’re on. One row means you won: Call the provider, then mark the row ‘completed’ and save the response. None means you lost: Read the row and return its saved response or tell the caller to retry later if it is still ‘started’.
One detail is easy to get wrong: Commit the claim before the provider call goes out. Otherwise, a crash rolls it back and erases the only record that a charge may be in flight.
The harder case is a winning request that crashes mid-charge: Its key is stuck at “started,” and every retry is told to wait for an answer that will never come. A stuck claim is the same unknown all over again: Once it has sat in “started” longer than any healthy call could take, ask the provider what actually happened before anyone charges again.
Same key, different request
The second gap appeared a week into production and broke the intent assumption: A caller reused one key for two different requests, $200 and $500, and the system returned the first request’s stored response without noticing the amount had changed.
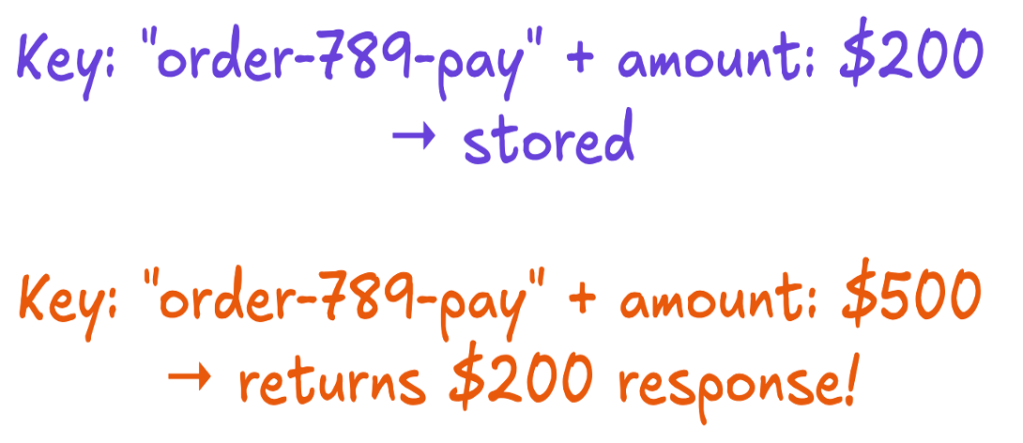
Violetta Pidvolotska
We fixed it by storing a fingerprint of the request’s contents next to the key, on the same insert, so a request that loses the claim race can still compare its fingerprint against the winner’s. If the fingerprints match, it’s a genuine retry. If they don’t, the key was reused for a different operation and we reject it.
That fix promptly rejected a valid retry. We had been fingerprinting the entire request, including a timestamp that changed between attempts and fields that arrived in a different order, so the fingerprints did not match.
A fingerprint has to capture what a request means rather than how its bytes are arranged. Hash a hand-picked list of business fields and you risk a silent collision: The one field nobody remembered to add lets two different requests match. Hash the whole request minus known noise like timestamps and the failure is loud instead: A missed volatile field rejects a valid retry. We chose loud, the fix came down to two lines:
intent = drop_fields(request.json, volatile={"client_ts", "trace_id"}) # strip known noise only
fingerprint = sha256(canonical_json(intent)) # canonical form: keys sorted, numbers and spacing normalizedEven “canonical” hides decisions. RFC 8785 pins them down, but it runs every number through an IEEE 754 double, which loses precision on large values, so money amounts are safer as strings or integer cents. Change the canonical form and every stored fingerprint stops matching, so we version it and store the version next to the fingerprint.
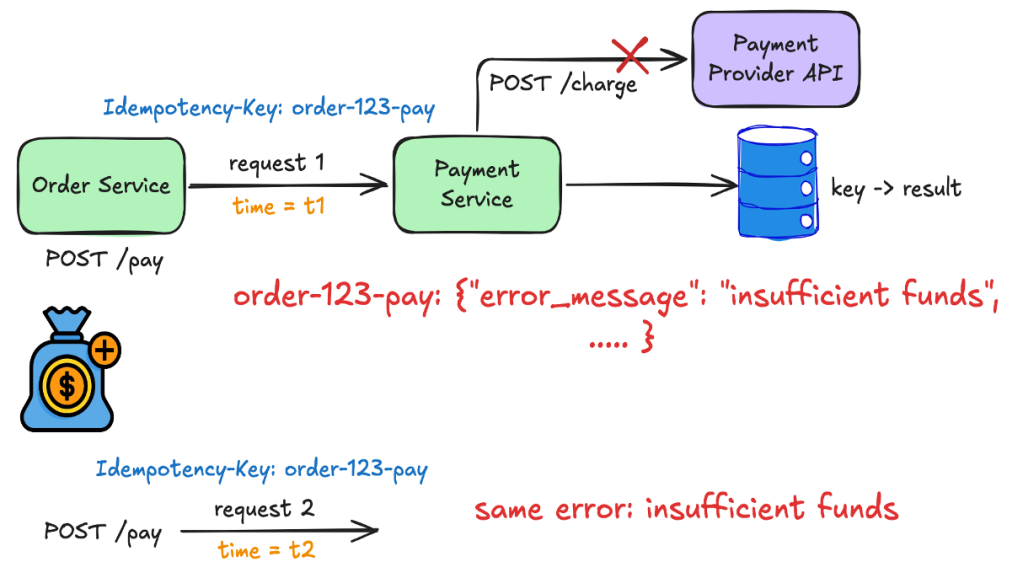
The error we cached
The third gap came in through support: A customer hit an insufficient-funds decline, added money, tried again with the same key and got the old “insufficient funds” back. The provider was never asked. The system had been caching every response, declines included, so the failure stuck to the key.
Violetta Pidvolotska
That forced the question behind the memory assumption: What is a key allowed to remember? The rule we landed on: cache only success.
A soft decline or a validation error releases the claim instead: The row flips back to claimable, fingerprint kept. The next attempt reclaims it with an update that only one retry can win and the customer who adds money gets a live attempt instead of a replay. Hard declines are the exception: A stolen-card response is final and that claim stays closed.
On a timeout, we don’t know whether the charge landed, so we ask the provider whether the charge already went through and act on the answer.
Where the guarantee runs out
The first three gaps were on endpoints under the team’s control. The fourth surfaced during reconciliation: A charge on an older provider’s statement with no matching internal record. That provider had no idempotency keys, and the guarantee had reached its boundary. We could not make it safe to call twice.
We got as close as we could: A pending record before the call, a status check before retrying, reconciliation to catch and refund whatever slips through. A window remains where the charge has landed and our record doesn’t know it yet. We kept shrinking that window, but we never managed to close it.
The database that holds the keys forces a decision of its own: When it is down, you either stop taking payments or take them unprotected. That choice is a business call. For a low-stakes write, cleaning up a rare duplicate can cost less than turning customers away. A payment is not low stakes, so we fail closed and stop taking payments until the store is back: A lost sale we can recover, and we had just spent a month learning what duplicates cost.
Questions I ask in design reviews
For anything that stores or changes data, I ask three questions:
- What happens if this runs twice? Ask it out loud for every write.
- Can we prove the answer? Run it twice in tests, in sequence and in parallel; the second run should change nothing.
- Where does the truth live when systems disagree? For payments, it’s the provider because their records show whether money actually moved. Settle whose answer wins before an incident does.
The key is a good idea and, in anything that moves money, a necessary one. It is just not a guarantee. The guarantee is the design around it: A claim that cannot race, an intent the fingerprint confirms, a memory that keeps only what is safe to replay and a boundary you have mapped in advance. That is the four-assumptions test. Every assumption gets tested eventually: You do it at design time or production does it for you.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?




{kind=link}